
 MyBaits Plus CURD
MyBaits Plus CURD
# MyBatis Plus CURD
学习MP BaseMapper 中的接口。更多的例如Service CURD接口、SimpleQuery工具类参考:CRUD 接口 (opens new window)。
下面用上节 SpringBoot + MyBatis + MP的工程测试。
# 插入操作
BaseMapper中插入方法定义
/**
* 插入一条记录
*
* @param entity 实体对象
*/
int insert(T entity);
测试:
@Test
public void testInsert() {
User user = new User();
user.setName("mp.insert");
user.setAge(18);
user.setEmail("mp.insert@baomidou.com");
userMapper.insert(user);
System.out.println(user);
// User(id=1650130102197522434, name=mp.insert, age=18, email=mp.insert@baomidou.com)
}
数据已经写⼊到了数据库,我们可以看到MP⽣成了ID的值并写⼊到了数据库,但我们期望的是数据库⾃增⻓,如何设置id的⽣成策略呢?MP⽀持的ID策略:
package com.baomidou.mybatisplus.annotation;
import lombok.Getter;
/**
* 生成ID类型枚举类
*
* @author hubin
* @since 2015-11-10
*/
@Getter
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO(0),
/**
* 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
*/
NONE(1),
/**
* 用户输入ID
* <p>该类型可以通过自己注册自动填充插件进行填充</p>
*/
INPUT(2),
/* 以下3种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 分配ID (主键类型为number或string),
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法)
*
* @since 3.3.0
*/
ASSIGN_ID(3),
/**
* 分配UUID (主键类型为 string)
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-",""))
*/
ASSIGN_UUID(4);
private final int key;
IdType(int key) {
this.key = key;
}
}
修改User对象:
@Data
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
private Integer age;
private String email;
}
然后修改user表的id改为自增,删除之前插入的数据,然后重跑测试用例,可以看到插入成功,控制台输出:
User(id=6, name=mp.insert, age=18, email=mp.insert@baomidou.com)
PS:实体对象通常与表互相映射,以下是实体对象可以使用的相关注解:
- @TableName:指定表名。如果表名与实体名称不一样,可以使用该注解声明;
- @TableField:指定字段的⼀些属性。可以解决如下问题:
- 如果字段与实体的属性不一致(非驼峰)
- 声明属性在表中不存在
- 字段不加⼊查询字段等等
# 更新操作
在MP中,更新操作主要有2种,⼀种是根据ID更新,另⼀种是根据条件更新。
# updateById
方法定义:
/**
* 根据 ID 修改
*
* @param entity 实体对象
*/
int updateById(@Param(Constants.ENTITY) T entity);
测试:
@Test
public void testUpdateById() {
User user = new User();
user.setId(6L);
user.setName("mp.updateById");
// 根据id更新,更新不为null的字段
userMapper.updateById(user);
System.out.println(userMapper.selectById(6L));
// User(id=6, name=mp.updateById, age=18, email=mp.insert@baomidou.com)
}
# update
方法定义:
/**
* 根据 whereEntity 条件,更新记录
*
* @param entity 实体对象 (set 条件值,可以为 null)
* @param updateWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
*/
int update(@Param(Constants.ENTITY) T entity, @Param(Constants.WRAPPER) Wrapper<T> updateWrapper);
测试:
@Test
public void testUpdate() {
// 1.使用QueryWrapper更新
User user = new User();
user.setName("mp.updateByCondition");
user.setAge(20);
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("id", 6);
userMapper.update(user, wrapper);
System.out.println(userMapper.selectById(6L));
// User(id=6, name=mp.updateByCondition, age=20, email=mp.insert@baomidou.com)
// 2.或者使用UpdateWrapper更新
UpdateWrapper<User> updateWrapper = new UpdateWrapper<>();
updateWrapper.eq("id", 6).set("name", "mp.updateByUpdateWrapper");
userMapper.update(null, updateWrapper);
System.out.println(userMapper.selectById(6L));
// User(id=6, name=mp.updateByUpdateWrapper, age=20, email=mp.insert@baomidou.com)
}
Wrapper条件构造器是MP非常重要的类,更多的⽤法可以看后⾯的介绍,或者看官网。
# 删除操作
# deleteById
⽅法定义:
/**
* 根据 ID 删除
*
* @param id 主键ID
*/
int deleteById(Serializable id);
测试用例:
@Test
public void testDeleteById() {
int i = userMapper.deleteById(6L);
System.out.println(i); // 1
System.out.println(userMapper.selectById(6L)); // null
}
# deleteByMap
方法定义:
/**
* 根据 columnMap 条件,删除记录
*
* @param columnMap 表字段 map 对象
*/
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);
重新执行插入数据,执行测试用例:
@Test
public void testDeleteByMap() {
// 删除条件,默认and连接
Map<String, Object> columnsMap = new HashMap<>();
columnsMap.put("age", 18);
columnsMap.put("name", "mp.insert");
int i = userMapper.deleteByMap(columnsMap);
System.out.println(i); // 1
System.out.println(userMapper.selectById(7L)); // null
}
# delete
方法定义:
/**
* 根据 entity 条件,删除记录
*
* @param queryWrapper 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句)
*/
int delete(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
重新执行插入数据,执行测试用例:
@Test
public void testDeleteByWrapper() {
// 将实体对象进⾏包装,包装为操作条件
User user = new User();
user.setAge(18);
user.setName("mp.insert");
QueryWrapper<User> wrapper = new QueryWrapper<>(user);
int i = userMapper.delete(wrapper);
System.out.println(i); // 1
}
# deleteBatchIds
方法定义:
/**
* 删除(根据ID 批量删除)
*
* @param idList 主键ID列表(不能为 null 以及 empty)
*/
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
插入多条数数据,执行测试用例:
@Test
public void testDeleteByIds() {
int i = userMapper.deleteBatchIds(Arrays.asList(9L, 10L, 11L));
System.out.println(i); // 3
}
# 查询操作
MP提供了多种查询操作,包括根据id查询、批量查询、查询单条数据、查询列表、分⻚查询等操作。
# selectById
方法定义:
/**
* 根据 ID 查询
*
* @param id 主键ID
*/
T selectById(Serializable id);
测试用例:
@Test
public void testSelectById() {
User user = userMapper.selectById(1L);
System.out.println(user);
// User(id=1, name=Jone, age=18, email=test1@baomidou.com)
}
# selectBatchIds
方法定义:
/**
* 查询(根据ID 批量查询)
*
* @param idList 主键ID列表(不能为 null 以及 empty)
*/
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);
测试用例:
@Test
public void testSelectBatchIds() {
List<User> users = userMapper.selectBatchIds(Arrays.asList(1L, 2L, 3L));
System.out.println(users);
// [User(id=1, name=Jone, age=18, email=test1@baomidou.com), User(id=2, name=Jack, age=20, email=test2@baomidou.com), User(id=3, name=Tom, age=28, email=test3@baomidou.com)]
}
# selectOne
方法定义:
/**
* 根据 entity 条件,查询一条记录
*
* @param queryWrapper 实体对象封装操作类(可以为 null)
*/
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
测试用例:
@Test
public void testSelectOne() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.eq("name", "Jone");
User user = userMapper.selectOne(wrapper);
System.out.println(user);
// User(id=1, name=Jone, age=18, email=test1@baomidou.com)
}
# selectCount
方法定义:
/**
* 根据 Wrapper 条件,查询总记录数
*
* @param queryWrapper 实体对象封装操作类(可以为 null)
*/
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
测试用例:
@Test
public void testSelectCount() {
// 年龄>=20
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.gt("age", 20);
Integer count = userMapper.selectCount(wrapper);
System.out.println(count);
// 3
}
# selectList
方法定义:
/**
* 根据 entity 条件,查询全部记录
*
* @param queryWrapper 实体对象封装操作类(可以为 null)
*/
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
测试用例:
@Test
public void testSelectList() {
// 年龄>=20
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.gt("age", 20);
List<User> users = userMapper.selectList(wrapper);
System.out.println(users);
// [User(id=3, name=Tom, age=28, email=test3@baomidou.com), User(id=4, name=Sandy, age=21, email=test4@baomidou.com), User(id=5, name=Billie, age=24, email=test5@baomidou.com)]
}
# selectPage
方法定义:
/**
* 根据 entity 条件,查询全部记录(并翻页)
*
* @param page 分页查询条件(可以为 RowBounds.DEFAULT)
* @param queryWrapper 实体对象封装操作类(可以为 null)
*/
<E extends IPage<T>> E selectPage(E page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
配置分页插件:
@Configuration
@MapperScan("org.example.hello.mp")
public class MybatisPlusConfig {
/**
* 新的分页插件
* 一缓和二缓遵循MyBatis的规则, 需要设置 MybatisConfiguration#useDeprecatedExecutor = false, 避免缓存出现问题(该属性会在旧插件移除后一同移除)
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
@Bean
public ConfigurationCustomizer configurationCustomizer() {
return configuration -> configuration.setUseGeneratedKeys(false);
}
}
测试用例:
@Test
public void testSelectPage() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
wrapper.gt("age", 20);
Page<User> page = new Page<>(1, 1);
IPage<User> userPage = userMapper.selectPage(page, wrapper);
System.out.println("数据总条数:" + userPage.getTotal());
System.out.println("总⻚数:" + userPage.getPages());
System.out.println(userPage.getRecords());
// 数据总条数:3
// 总⻚数:3
// [User(id=3, name=Tom, age=28, email=test3@baomidou.com)]
}
# SQL注⼊的原理
前⾯我们已经知道,MP在启动后会将 BaseMapper中的⼀系列的⽅法注册到 meppedStatements中,那么究竟是如何注⼊的呢?流程⼜是怎么样的?下⾯我们将⼀起来分析下。
在MP中,ISqlInjector负责SQL的注⼊⼯作,它是⼀个接⼝,AbstractSqlInjector是它的实现类,实现关系如下:
ISqlInjector (com.baomidou.mybatisplus.core.injector)
--AbstractSqlInjector (com.baomidou.mybatisplus.core.injector)
----DefaultSqlInjector (com.baomidou.mybatisplus.core.injector)
先看看 AbstractSqlInjector的定义:
public interface ISqlInjector {
/**
* 检查SQL是否注入(已经注入过不再注入)
*
* @param builderAssistant mapper 信息
* @param mapperClass mapper 接口的 class 对象
*/
void inspectInject(MapperBuilderAssistant builderAssistant, Class<?> mapperClass);
}
在 AbstractSqlInjector中,主要是由 inspectInject()⽅法进⾏注⼊的,如下:
@Override
public void inspectInject(MapperBuilderAssistant builderAssistant, Class<?> mapperClass) {
Class<?> modelClass = extractModelClass(mapperClass);
if (modelClass != null) {
String className = mapperClass.toString();
Set<String> mapperRegistryCache = GlobalConfigUtils.getMapperRegistryCache(builderAssistant.getConfiguration());
if (!mapperRegistryCache.contains(className)) {
List<AbstractMethod> methodList = this.getMethodList(mapperClass);
if (CollectionUtils.isNotEmpty(methodList)) {
TableInfo tableInfo = TableInfoHelper.initTableInfo(builderAssistant, modelClass);
// 循环注入自定义方法
methodList.forEach(m -> m.inject(builderAssistant, mapperClass, modelClass, tableInfo));
} else {
logger.debug(mapperClass.toString() + ", No effective injection method was found.");
}
mapperRegistryCache.add(className);
}
}
}
在实现⽅法中, methodList.forEach(m -> m.inject(builderAssistant, mapperClass, modelClass, tableInfo));是关键,循环遍历⽅法,进⾏注⼊。
m.inject方法,最终调⽤抽象⽅法 injectMappedStatement进⾏真正的注⼊:
/**
* 注入自定义 MappedStatement
*
* @param mapperClass mapper 接口
* @param modelClass mapper 泛型
* @param tableInfo 数据库表反射信息
* @return MappedStatement
*/
public abstract MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo);
查看该⽅法的实现:
AbstractMethod (com.baomidou.mybatisplus.core.injector)
--DeleteByMap (com.baomidou.mybatisplus.core.injector.methods)
--SelectMapsPage (com.baomidou.mybatisplus.core.injector.methods)
--SelectBatchByIds (com.baomidou.mybatisplus.core.injector.methods)
--SelectCount (com.baomidou.mybatisplus.core.injector.methods)
--InsertBatchSomeColumn (com.baomidou.mybatisplus.extension.injector.methods)
--SelectObjs (com.baomidou.mybatisplus.core.injector.methods)
--SelectOne (com.baomidou.mybatisplus.core.injector.methods)
--SelectList (com.baomidou.mybatisplus.core.injector.methods)
--DeleteById (com.baomidou.mybatisplus.core.injector.methods)
--Upsert (com.baomidou.mybatisplus.extension.injector.methods)
--Insert (com.baomidou.mybatisplus.core.injector.methods)
--Update (com.baomidou.mybatisplus.core.injector.methods)
--UpdateById (com.baomidou.mybatisplus.core.injector.methods)
--SelectMaps (com.baomidou.mybatisplus.core.injector.methods)
--AlwaysUpdateSomeColumnById (com.baomidou.mybatisplus.extension.injector.methods)
--Delete (com.baomidou.mybatisplus.core.injector.methods)
--SelectByMap (com.baomidou.mybatisplus.core.injector.methods)
--DeleteBatchByIds (com.baomidou.mybatisplus.core.injector.methods)
--SelectById (com.baomidou.mybatisplus.core.injector.methods)
--LogicDeleteByIdWithFill (com.baomidou.mybatisplus.extension.injector.methods)
--SelectPage (com.baomidou.mybatisplus.core.injector.methods)
以SelectById为例查看:
/**
* 根据ID 查询一条数据
*
* @author hubin
* @since 2018-04-06
*/
public class SelectById extends AbstractMethod {
@Override
public MappedStatement injectMappedStatement(Class<?> mapperClass, Class<?> modelClass, TableInfo tableInfo) {
SqlMethod sqlMethod = SqlMethod.SELECT_BY_ID;
SqlSource sqlSource = new RawSqlSource(configuration, String.format(sqlMethod.getSql(),
sqlSelectColumns(tableInfo, false),
tableInfo.getTableName(), tableInfo.getKeyColumn(), tableInfo.getKeyProperty(),
tableInfo.getLogicDeleteSql(true, true)), Object.class);
return this.addSelectMappedStatementForTable(mapperClass, getMethod(sqlMethod), sqlSource, tableInfo);
}
}
可以看到,⽣成了SqlSource对象,再将SQL通过 addSelectMappedStatement⽅法添加到 meppedStatements中。
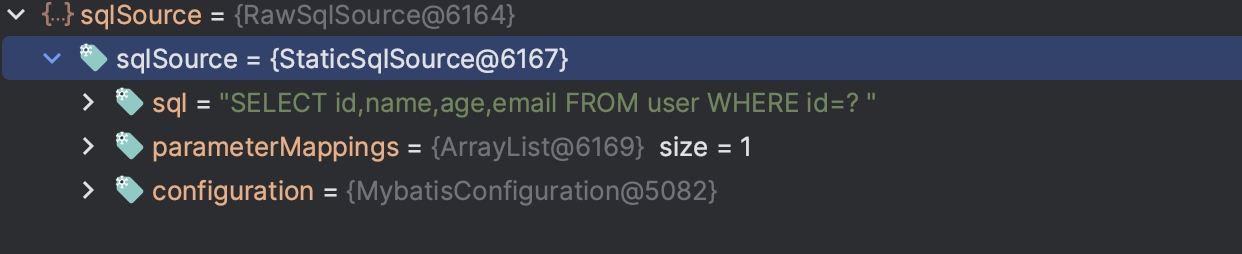
# SimpleQuery 工具类
MP对CURD的操作提供了一个工具类:SimpleQuery。
对selectList查询后的结果用Stream流进行了一些封装,使其可以返回一些指定结果,简洁了api的调用
需要项目中已注入对应实体的BaseMapper
使用方式见: 测试用例 (opens new window)
对于下方参数
peeks,其类型为Consumer...,可一直往后叠加操作例如:List<Long> ids = SimpleQuery.list(Wrappers.lambdaQuery(), Entity::getId, System.out::println, user -> userNames.add(user.getName()));
下面是他提供的方法:
# keyMap
// 查询表内记录,封装返回为Map<属性,实体>
Map<A, E> keyMap(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks);
// 查询表内记录,封装返回为Map<属性,实体>,考虑了并行流的情况
Map<A, E> keyMap(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, boolean isParallel, Consumer<E>... peeks);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| E | entity | 实体对象 |
| A | attribute | 实体属性类型,也是map中key的类型 |
LambdaQueryWrapper<E> | wrapper | 支持lambda的条件构造器 |
| SFunction<E, A> | sFunction | 实体中属性的getter,用于封装后map中作为key的条件 |
| boolean | isParallel | 为true时底层使用并行流执行 |
Consumer<E>... | peeks | 可叠加的后续操作 |
# map
// 查询表内记录,封装返回为Map<属性,属性>
Map<A, P> map(LambdaQueryWrapper<E> wrapper, SFunction<E, A> keyFunc, SFunction<E, P> valueFunc, Consumer<E>... peeks);
// 查询表内记录,封装返回为Map<属性,属性>,考虑了并行流的情况
Map<A, P> map(LambdaQueryWrapper<E> wrapper, SFunction<E, A> keyFunc, SFunction<E, P> valueFunc, boolean isParallel, Consumer<E>... peeks);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| E | entity | 实体对象 |
| A | attribute | 实体属性类型,也是map中key的类型 |
| P | attribute | 实体属性类型,也是map中value的类型 |
LambdaQueryWrapper<E> | wrapper | 支持lambda的条件构造器 |
| SFunction<E, A> | keyFunc | 封装后map中作为key的条件 |
| SFunction<E, P> | valueFunc | 封装后map中作为value的条件 |
| boolean | isParallel | 为true时底层使用并行流执行 |
Consumer<E>... | peeks | 可叠加的后续操作 |
# group
// 查询表内记录,封装返回为Map<属性,List<实体>>
Map<K, List<T>> group(LambdaQueryWrapper<T> wrapper, SFunction<T, A> sFunction, Consumer<T>... peeks);
// 查询表内记录,封装返回为Map<属性,List<实体>>,考虑了并行流的情况
Map<K, List<T>> group(LambdaQueryWrapper<T> wrapper, SFunction<T, K> sFunction, boolean isParallel, Consumer<T>... peeks);
// 查询表内记录,封装返回为Map<属性,分组后对集合进行的下游收集器>
M group(LambdaQueryWrapper<T> wrapper, SFunction<T, K> sFunction, Collector<? super T, A, D> downstream, Consumer<T>... peeks);
// 查询表内记录,封装返回为Map<属性,分组后对集合进行的下游收集器>,考虑了并行流的情况
M group(LambdaQueryWrapper<T> wrapper, SFunction<T, K> sFunction, Collector<? super T, A, D> downstream, boolean isParallel, Consumer<T>... peeks);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 |
| K | attribute | 实体属性类型,也是map中key的类型 |
| D | - | 下游收集器返回类型,也是map中value的类型 |
| A | - | 下游操作中间类型 |
| M | - | 最终结束返回的Map<K, D> |
LambdaQueryWrapper<E> | wrapper | 支持lambda的条件构造器 |
| SFunction<E, A> | sFunction | 分组依据,封装后map中作为key的条件 |
| Collector<T, A, D> | downstream | 下游收集器 |
| boolean | isParallel | 为true时底层使用并行流执行 |
Consumer<T>... | peeks | 可叠加的后续操作 |
# list
// 查询表内记录,封装返回为List<属性>
List<A> list(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, Consumer<E>... peeks);
// 查询表内记录,封装返回为List<属性>,考虑了并行流的情况
List<A> list(LambdaQueryWrapper<E> wrapper, SFunction<E, A> sFunction, boolean isParallel, Consumer<E>... peeks);
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| E | entity | 实体对象 |
| A | attribute | 实体属性类型,也是list中元素的类型 |
LambdaQueryWrapper<E> | wrapper | 支持lambda的条件构造器 |
| SFunction<E, A> | sFunction | 封装后list中的元素 |
| boolean | isParallel | 为true时底层使用并行流执行 |
Consumer<E>... | peeks | 可叠加的后续操作 |