
 MySQL性能优化手册
MySQL性能优化手册
# MySQL性能优化手册
作为一个合格的程序员或者DBA,问题一定要多方位进行考虑。这里总结MySQL优化的四个主要维度、MySQL相关开发规范,以及优化其他的考虑方向如架构优化。
# 四个纬度
MySQL优化可以从四个角度入手:SQL语句及索引、表结构设计、系统配置、硬件配置。
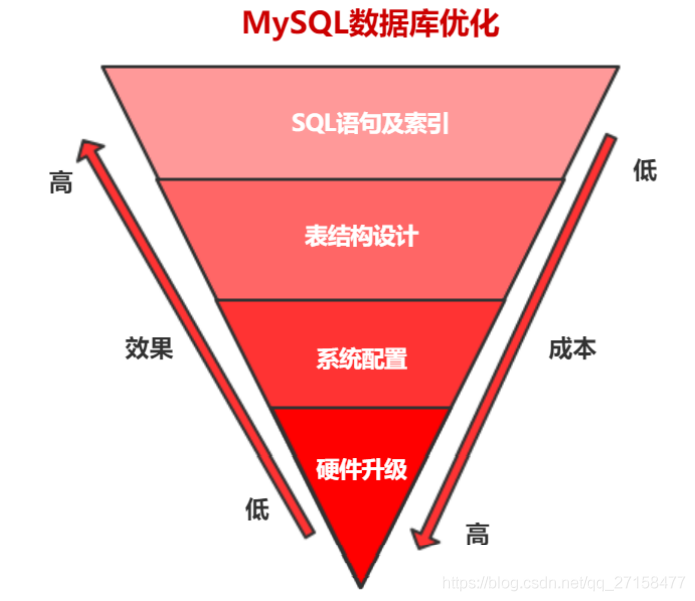
# 硬件升级
硬件方面的优化可以从CPU、内存、硬盘、网络入手,但是这个优化手段成本高但效果往往是最差的。这里不再多的赘述,也不推荐。
# 系统配置
# 服务端系统选择
常使用Linux作为服务端的系统,本地开发的话可以随意。Linux系统版本和MySQL版本选择稳定的版本即可。
# 保证从内存读取
MySQL会在内存中保存一定的数据,通过LRU(最近最少使用)算法将不常访问的数据保存在硬盘文件中。 尽可能的扩大内存中的数据量,将数据保存在内存中,从内存中读取数据,可以提升MySQL性能。这里针对InnoDB的内存中的Buffer Pool进行优化,常用命令以及参数:
# 查看page页大小
show variables like '%innodb_page_size%';
# 查看lru list中old列表参数
show variables like '%innodb_old%';
# 查看buffer pool参数
show variables like '%innodb_buffer%';
# 配置文件中建议配置
# innodb_buffer_pool_size设置为总内存大小的60%-80%,
# innodb_buffer_pool_instances可以设置为多个,这样可以避免缓存争夺。
# 系统预热
数据预热相当于将磁盘中的数据提前放入BufferPool内存缓冲池内。一定程度提升了读取速度(一般运维处理,开发不管)。
对于InnoDB,这里提供一份预热SQL脚本:
SELECT DISTINCT
CONCAT(
'SELECT ',
ndxcollist,
' FROM ',
db,
'.',
tb,
' ORDER BY ',
ndxcollist,
';'
) SelectQueryToLoadCache
FROM
(
SELECT
ENGINE,
table_schema db,
table_name tb,
index_name,
GROUP_CONCAT(
column_name
ORDER BY
seq_in_index
) ndxcollist
FROM
(
SELECT
B. ENGINE,
A.table_schema,
A.table_name,
A.index_name,
A.column_name,
A.seq_in_index
FROM
information_schema.statistics A
INNER JOIN (
SELECT
ENGINE,
table_schema,
table_name
FROM
information_schema. TABLES
WHERE
ENGINE = 'InnoDB'
) B USING (table_schema, table_name)
WHERE
B.table_schema NOT IN (
'information_schema',
'mysql'
)
ORDER BY
table_schema,
table_name,
index_name,
seq_in_index
) A
GROUP BY
table_schema,
table_name,
index_name
) AA
ORDER BY
db,
tb;
脚本保存为loadtomem.sql文件
执行命令:
mysql -uroot -proot -AN < /root/loadtomem.sql > /root/loadtomem.sql
在需要数据预热时(一般为重启MySQL服务)执行:
mysql -uroot < /root/loadtomem.sql > /dev/null 2>&1
# 降低磁盘写入次数
增大redo log,减少刷盘次数:redolog是重做日志,用于保证数据的一致。减少落盘相当于减少了系统IO操作。
nnodb_log_file_size 建议设置为 0.25 * innodb_buffer_pool_size通用查询日志、慢查询日志可以不开 ,binlog需要打开:通用查询和慢查询日志也是要落盘的,可以根据实际情况开启,如果不需要使用的话就可以关掉。binlog用于恢复和主从复制,这个可以开启。
# 慢查询日志 show variables like 'slow_query_log%' # 通用查询日志 show variables like '%general%'; # 错误日志 show variables like '%log_error%' # 二进制日志 show variables like '%binlog%';写redo log策略
innodb_flush_log_at_trx_commit设置为0或2:0:每隔1秒写日志文件和刷盘操作(写日志文件LogBuffer-->OS cache,刷盘OS cache-->磁盘文件),最多丢失1秒数据 1:事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁IO操作 2:事务提交,立刻写日志文件,每隔1秒钟进行刷盘操作
# 表结构设计优化
- 设计中间表:设计中间表,一般针对于统计分析功能,或者实时性不高的需求(报表统计,数据分析等系统)。
- 设计冗余字段:为减少关联查询,创建合理的冗余字段(创建冗余字段还需要注意数据一致性问题)。这里分库分表时较为常用。
- 拆表:对于字段太多的大表,考虑拆表(比如一个表有100多个字段) 对于表中经常不被使用的字段或者存储数据比较多的字段,考虑拆表。
- 主键优化:每张表建议都要有一个主键(主键索引),而且主键类型最好是int类型,建议自增主键(分布式系统的情况下建议雪花算法)
- 字段的设计:
- 使用尽量小的存储类型。数据库中的表越小,在它上面执行的查询也就会越快。 因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小。
- 尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。
- 使用tinyint代替enum
- 时间字段使用datetime
- varchar不要过长声明
- 减少宽表的设计(binlog)
- 减少使用text等大字段
# SQL语句与索引优化
SQL语句建议,更多见阿里MySQL开发规范:
- select必须指明字段名称
- 使用JOIN的优化
- 避免在where子句对字段进行表达式操作
- 避免隐式类型转换
- 避免使用%前缀模糊查询
- in包含的值不应过多
- 如果限制条件中其他字段没有索引,尽量少用OR
- 区分in和exists、not in和not exists
- 尽量用union all代替union
- 只需要一条数据时,使用limit 1
- 使用合理分页方式提高分页效率
- 必要时可以使用force index强制走某个索引
- 使用联合索引时注意范围查询
- 避免大SQL、大批量、复杂计算
# 开发规范
- Java开发手册(嵩山版) (opens new window):见MySQL 数据库规章节。
# 架构优化
- 主从架构
- 读写分离
- 分库分表
- 单库表数量控制在2000以内
- 单表分表控制在1024以内
- 单表字段控制在50以内
# 减少数据库访问
- 本地缓存
- 分布式缓存
上次更新: 5/30/2023, 11:09:19 PM