
 读写分离剖析
读写分离剖析
# 读写分离剖析
# 概述
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库,进一步的提升系统的处理能力。
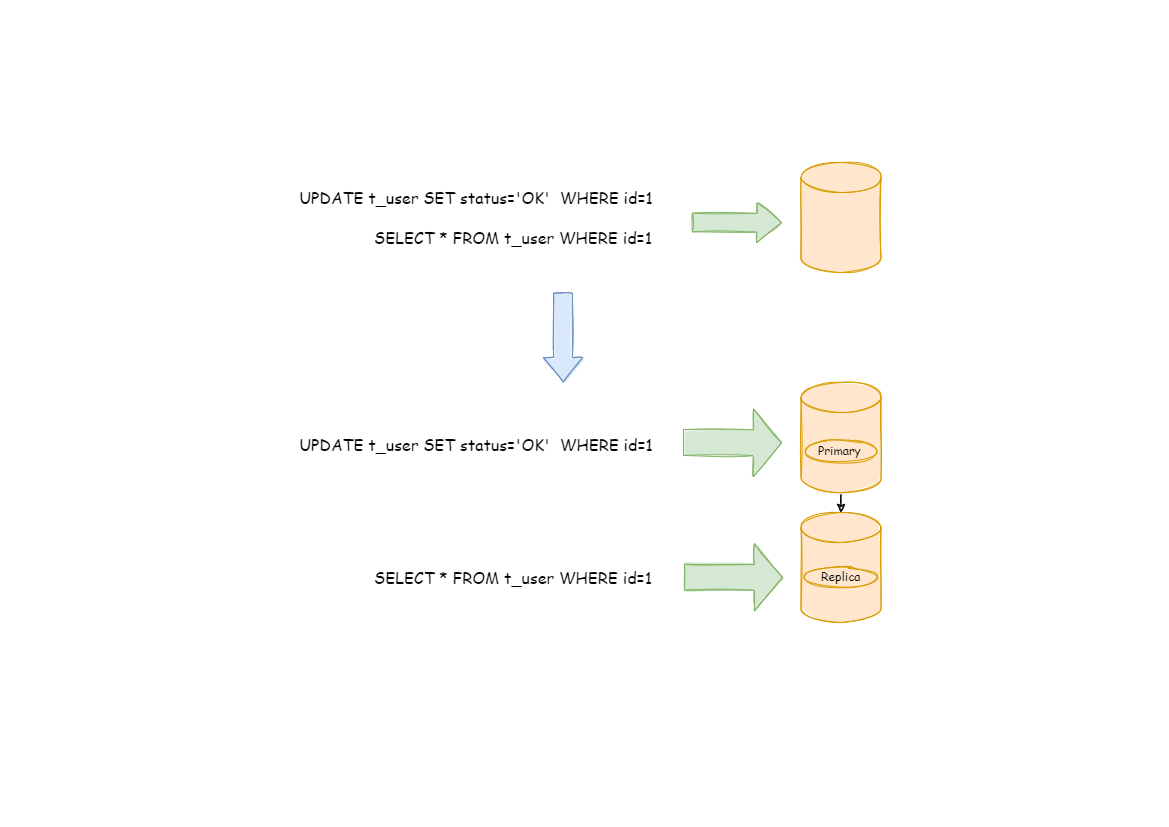
- 主从架构:读写分离,目的是高可用、读写扩展。主从库内容相同,根据SQL语义进行路由。
- 分库分表架构:数据分片,目的读写扩展、存储扩容。库和表内容不同,根据分片配置进行路由。
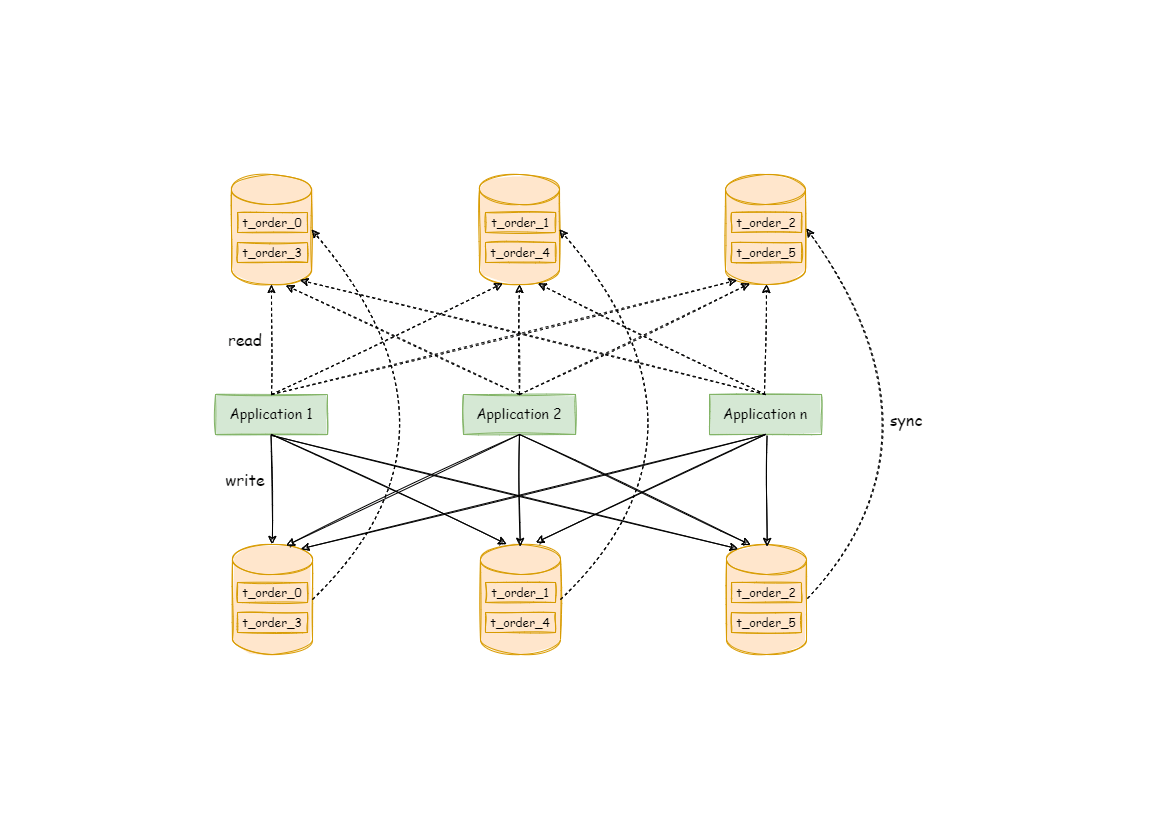
将水平分片和读写分离联合使用,能够更加有效的提升系统性能, 下图展现了将分库分表与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系:
# 应用方案
# 简单读写分离
在数据量不是很多的情况下,我们可以将数据库进行读写分离,以应对高并发的需求,通过水平扩展从库,来缓解查询的压力。如下:

# 分表+读写分离
在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。

# 分库分表+读写分离
在数据量继续扩大,这时可以考虑分库分表,将数据存储在不同数据库的不同表中,如下:

透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是ShardingSphere读写分离模块的主要设计目标。
# 使用规范
# 核心功能
- 提供一主多从的读写分离配置。仅支持单主库,可以支持独立使用,也可以配合分库分表使用
- 独立使用读写分离,支持SQL透传。不需要SQL改写流程
- 同一线程且同一数据库连接内,能保证数据一致性。如果有写入操作,后续的读操作均从主库读取。
- 基于Hint的强制主库路由。可以强制路由走主库查询实时数据,避免主从同步数据延迟。
# 不支持项
- 主库和从库的数据同步
- 主库和从库的数据同步延迟
- 主库双写或多写
- 跨主库和从库之间的事务的数据不一致。建议在主从架构中,事务中的读写均用主库操作。
# 常见配置
这里记录YAML的配置方式,其他见请参见用户手册 (opens new window)。
rules:
- !READWRITE_SPLITTING
dataSources:
<data-source-name> (+): # 读写分离逻辑数据源名称
type: # 读写分离类型,比如:Static,Dynamic
props:
auto-aware-data-source-name: # 自动发现数据源名称(与数据库发现配合使用)
write-data-source-name: # 写库数据源名称
read-data-source-names: # 读库数据源名称,多个从数据源用逗号分隔
loadBalancerName: # 负载均衡算法名称
# 负载均衡算法配置
loadBalancers:
<load-balancer-name> (+): # 负载均衡算法名称
type: # 负载均衡算法类型
props: # 负载均衡算法属性配置
# ...
上次更新: 5/30/2023, 11:42:20 PM